Видео с ютуба Token Per Second Benchmarks

LLM Speed Tiers Explained: What TPS (Token Per Second) Actually Feels Like

Fastest 1000000 tokens

The Local LLM Lie Nobody Talks About: Why "Tokens Per Second" is a Scam for AI Agents
The Token Arbitrage: Groq vs. DeepInfra vs. Cerebras vs fireworks (2025 Benchmark)
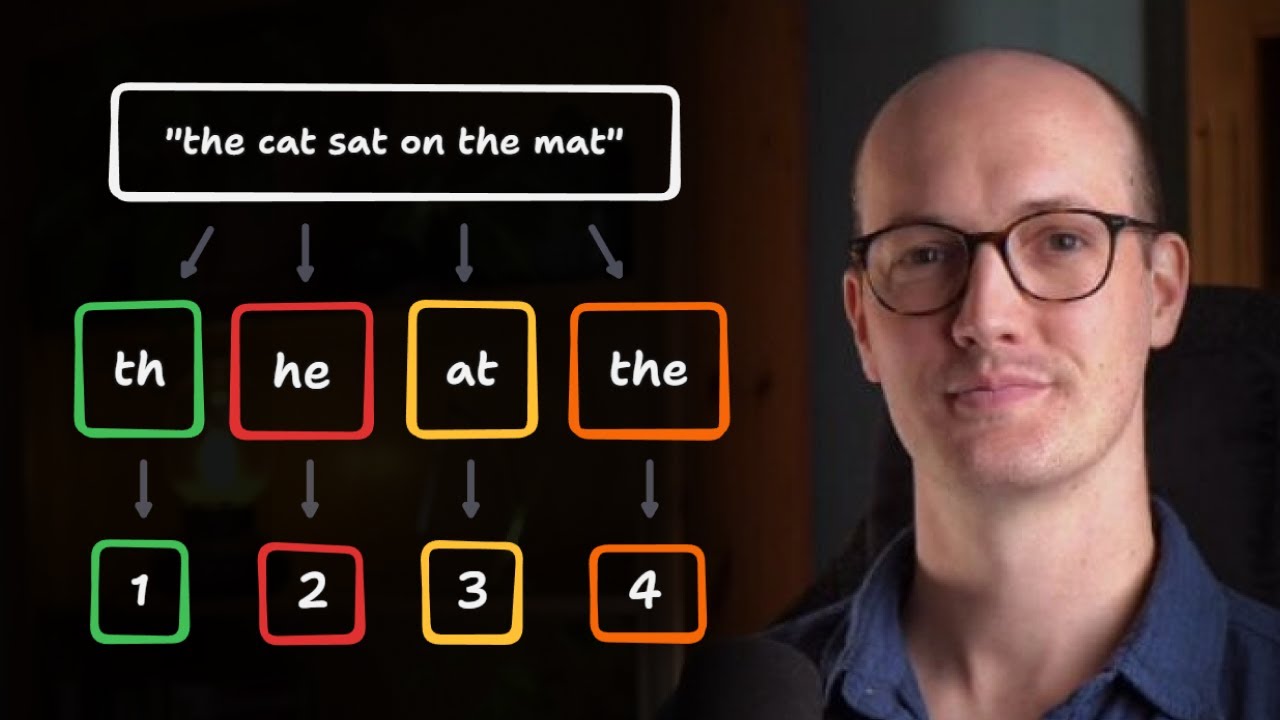
Большинство разработчиков не понимают, как работают токены LLM.

LLM Inference Benchmark 2026: Every GPU Ranked by Tokens Per Dollar

100 Tokens per Second from a Lunchbox

I Was Not Expecting This! 120 BILLION Params, 120 Tokens PER SECOND (feat llama.cpp)

New Mercury 2 Breaks The Latency Wall At 1k Tokens per Second (Destroys GPTs)

LM Studio MTP Token Speed Test | GRM 2.6 & Qwen 3.6 27B

Running Gemma 3 1B on Low-Spec PC | CPU-Only Test & Token Speed Benchmark
AI Models Tokens Per Second LMStudio Framework Desktop 128gb 96GB VRAM Test Review #wisebuyreviews

Clarifai преодолела отметку в 400 токенов в секунду на KIMI K2.5 - Основной доклад на GTC
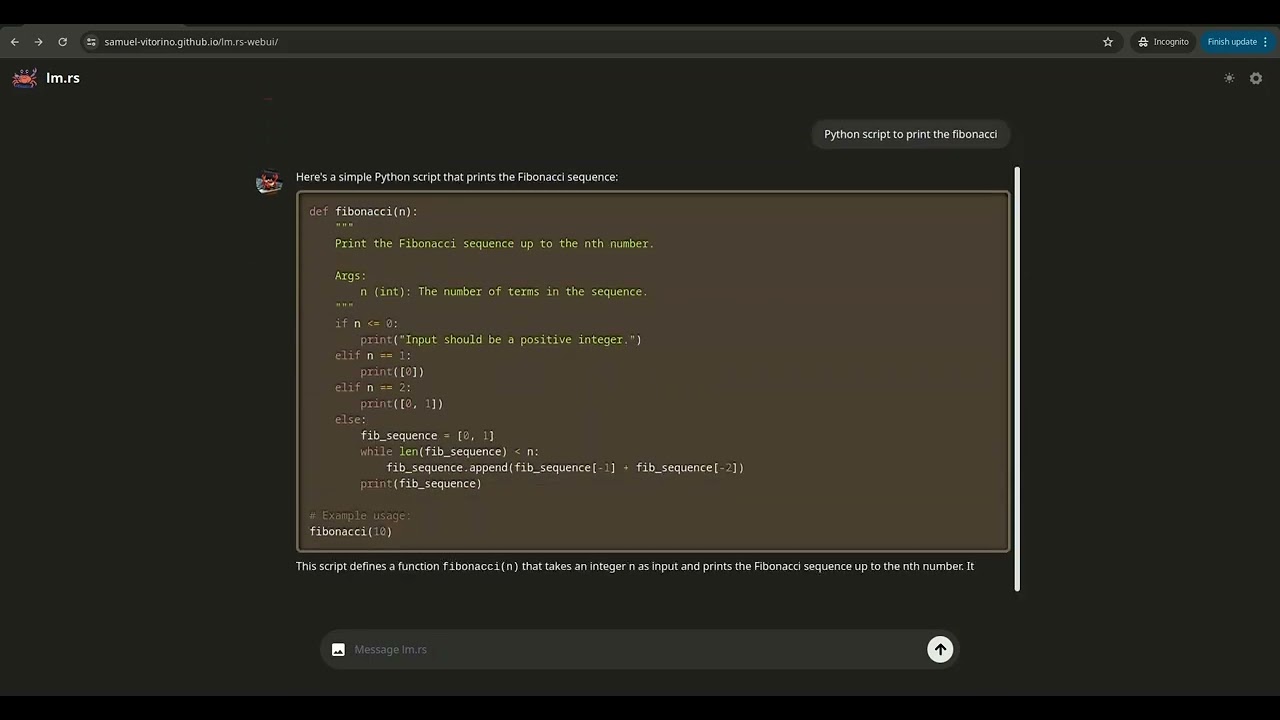
Llama 3.2 1B running at 50 tokens per second on the CPU with lm.rs

How to Run a Trillion-Parameter AI at 1,000 Tokens a Second

LLM Inference Benchmark 2026: Every GPU Ranked by Tokens Per Dollar
Deploy DiffusionGemma on GPU Cloud for 1,400+ Tokens Per Second

Tokens per Watt: The New Benchmark for AI Data Center Efficiency